Best practices for implementing a hybrid database system
In some circumstances, migrating from one or more relational database management systems (RDBMS) to Amazon DynamoDB might not be advantageous. In these cases, it might be preferable to create a hybrid system.
If you don't want to migrate everything to DynamoDB
For example, some organizations have large investments in the code that produces a multitude of reports needed for accounting and operations. The time it takes to generate a report is not important to them. The flexibility of a relational system is well suited to this kind of task, and re-creating all those reports in a NoSQL context might be prohibitively difficult.
Some organizations also maintain a variety of legacy relational systems that they have acquired or inherited over decades. Migrating data from these systems might be too risky and expensive to justify the effort.
However, the same organizations may now find that their operations depend on high-traffic customer-facing websites, where millisecond response is essential. Relational systems can't scale to meet this requirement except at huge (and often unacceptable) expense.
In these situations, the answer might be to create a hybrid system, in which DynamoDB creates a materialized view of data stored in one or more relational systems and handles high-traffic requests against this view. This type of system can potentially reduce costs by eliminating server hardware, maintenance, and RDBMS licenses that were previously needed to handle customer-facing traffic.
How a hybrid system can be implemented
DynamoDB can take advantage of DynamoDB Streams and AWS Lambda to integrate seamlessly with one or more existing relational database systems:
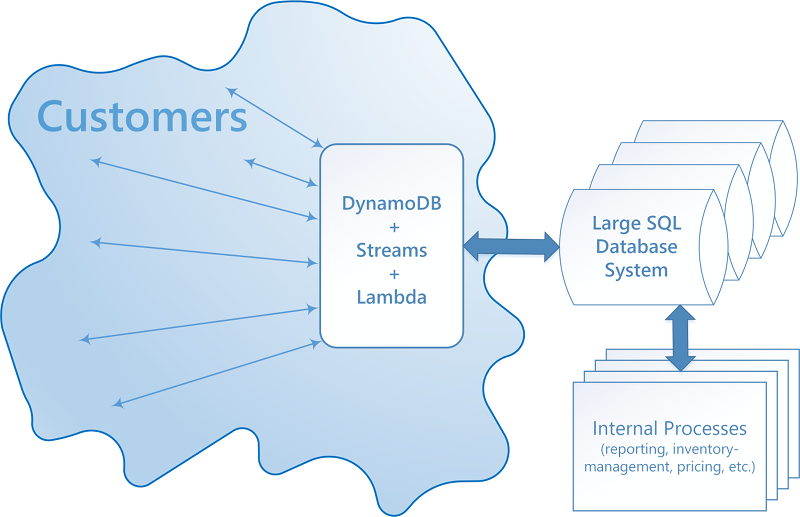
A system that integrates DynamoDB Streams and AWS Lambda can provide several advantages:
-
It can operate as a persisted cache of materialized views.
-
It can be set up to fill gradually with data as that data is queried for, and as data is modified in the SQL system. This means that the entire view does not need to be pre-populated. This in turn means that provisioned throughput capacity is more likely to be used efficiently.
-
It has low administrative costs and is highly available and reliable.
For this kind of integration to be implemented, essentially three kinds of interoperation must be provided.
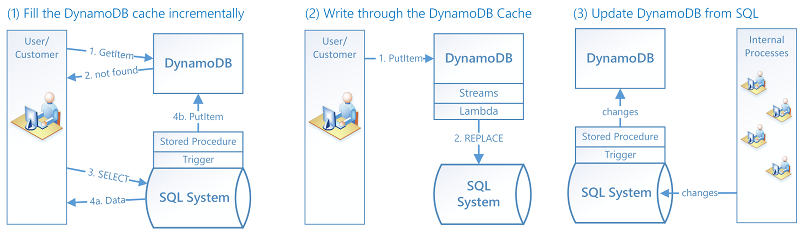
-
Fill the DynamoDB cache incrementally. When an item is queried, look for it first in DynamoDB. If it is not there, look for it in the SQL system, and load it into DynamoDB.
-
Write through a DynamoDB cache. When a customer changes a value in DynamoDB, a Lambda function is triggered to write the new data back to the SQL system.
-
Update DynamoDB from the SQL system. When internal processes such as inventory management or pricing change a value in the SQL system, a stored procedure is triggered to propagate the change to the DynamoDB materialized view.
These operations are straightforward, and not all of them are needed for every scenario.
A hybrid solution can also be useful when you want to rely primarily on DynamoDB, but you also want to maintain a small relational system for one-time queries, or for operations that need special security or that are not time-critical.
