What is S3 Express One Zone?
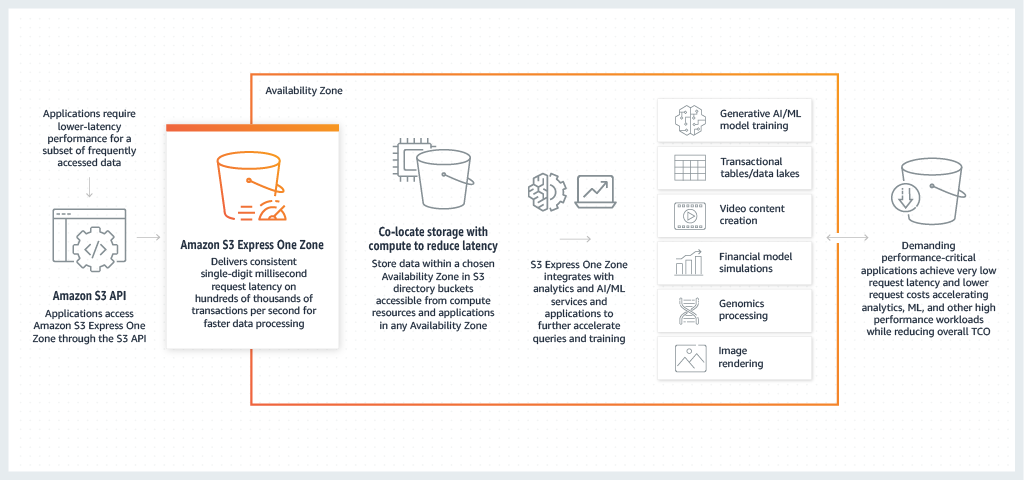
Amazon S3 Express One Zone is a high-performance, single-zone Amazon S3 storage class that is purpose-built to deliver consistent, single-digit millisecond data access for your most latency-sensitive applications. S3 Express One Zone is the lowest latency cloud-object storage class available today, with data access speeds up to 10x faster and with request costs 50 percent lower than S3 Standard. Applications can benefit immediately from requests being completed up to an order of magnitude faster. S3 Express One Zone provides similar performance elasticity as other S3 storage classes.
As with other Amazon S3 storage classes, you don't need to plan or provision capacity or throughput requirements in advance. You can scale your storage up or down, based on need, and access your data through the Amazon S3 API.
S3 Express One Zone is the first S3 storage class where you can select a single Availability Zone with the option to co-locate your object storage with your compute resources, which provides the highest possible access speed. Additionally, to further increase access speed and support hundreds of thousands of requests per second, data in S3 Express One Zone storage class is stored in a new bucket type: an Amazon S3 directory bucket. Each directory bucket can support hundreds of thousands of transactions per second (TPS), irrespective of key names or access pattern.
The Amazon S3 Express One Zone storage class is designed for 99.95 percent availability within a single Availability Zone and is backed
by the Amazon S3 Service Level Agreement
S3 Express One Zone is ideal for any application where it's important to minimize the latency required to access an object. Such applications can be human-interactive workflows, like video editing, where creative professionals need responsive access to content from their user interfaces. S3 Express One Zone also benefits analytics and machine learning workloads that have similar responsiveness requirements from their data, especially workloads with lots of smaller accesses or large numbers of random accesses. S3 Express One Zone can be used with other AWS services to support analytics and artificial intelligence and machine learning (AI/ML) workloads, such as Amazon EMR, Amazon SageMaker, and Amazon Athena.
When using S3 Express One Zone, you can interact with your directory bucket in a virtual private cloud (VPC) by using a gateway VPC endpoint. With a gateway endpoint, you can access S3 Express One Zone directory buckets from your VPC without an internet gateway or NAT device for your VPC, and at no additional cost.
You can use many of the same Amazon S3 API operations and features with directory buckets that you use with general purpose buckets and other storage classes. These include Mountpoint for Amazon S3, server-side encryption with Amazon S3 managed keys (SSE-S3), S3 Batch Operations, and S3 Block Public Access. You can access S3 Express One Zone by using the Amazon S3 console, AWS Command Line Interface (AWS CLI), AWS SDKs, and the Amazon S3 REST API.
For more information about S3 Express One Zone, see the following topics.
Overview
To optimize performance and reduce latency, S3 Express One Zone introduces the following new concepts.
Single Availability Zone
The Amazon S3 Express One Zone storage class is designed for 99.95 percent availability within a single Availability Zone and is backed
by the Amazon S3 Service Level Agreement
An Availability Zone is one or more discrete data centers with redundant power, networking, and connectivity in an AWS Region. When you create a directory bucket, you choose the Availability Zone and AWS Region where your bucket will be located.
Directory buckets
There are two types of Amazon S3 buckets: S3 general purpose buckets and S3 directory buckets. General purpose buckets are the default Amazon S3 bucket type that is used for the vast majority of S3 use cases. Directory buckets use only the S3 Express One Zone storage class, which is designed for workloads or performance-critical applications that require consistent single-digit millisecond latency. Choose the bucket type that best fits your application and performance requirements.
Directory buckets organize data hierarchically into directories, as opposed to the flat storage structure of general purpose buckets. There aren't prefix limits for directory buckets, and individual directories can scale horizontally.
Directory buckets use the S3 Express One Zone storage class, which is built to be used by performance sensitive applications. With S3 Express One Zone, you can select a single Availability Zone with the option to co-locate your object storage with your compute resources, which provides the highest possible access speed. This is unlike general purpose buckets, which redundantly store objects across multiple Availability Zones in AWS Regions.
For more information about directory buckets, see Directory buckets. For more information about general purpose buckets, see Buckets overview.
Endpoints and gateway VPC endpoints
Bucket-management API operations for directory buckets are available through a
Regional endpoint and are referred to as Regional endpoint API operations. Examples
of Regional endpoint API operations are CreateBucket and
DeleteBucket. After you create a directory bucket, you can use
Zonal endpoint API operations to upload and manage the objects in your directory
bucket. Zonal endpoint API operations are available through a Zonal endpoint.
Examples of Zonal endpoint API operations are PutObject and
CopyObject.
You can access S3 Express One Zone from your VPC by using gateway VPC endpoints. After you create a gateway endpoint, you can add it as a target in your route table for traffic destined from your VPC to S3 Express One Zone. As with Amazon S3, there is no additional charge for using gateway endpoints. For more information about how to configure gateway VPC endpoints, see Networking for S3 Express One Zone
Session-based authorization
With S3 Express One Zone, you authenticate and authorize requests through a new
session-based mechanism that is optimized to provide the lowest latency. You can use
CreateSession to request temporary credentials that provide
low-latency access to your bucket. These temporary credentials are scoped to a
specific S3 directory bucket. Session tokens are used only with Zonal (object-level)
operations (with the exception of CopyObject). For more information, see CreateSession authorization.
The supported AWS SDKs for S3 Express One Zone handle session establishment and refreshment on your behalf. To protect your sessions, temporary security credentials expire after 5 minutes. After you download and install the AWS SDKs and configure the necessary AWS Identity and Access Management (IAM) permissions, you can immediately start using API operations.
Features of S3 Express One Zone
The following S3 features are available for S3 Express One Zone. For a complete list of supported API operationss and unsupported features, see How is S3 Express One Zone different?.
Access management and security
With directory buckets, you can use the following features to audit and manage access. By default, directory buckets are private and can be accessed only by users who are explicitly granted access. Unlike general purpose buckets, which can set the access control boundary at the bucket, prefix, or object tag level, the access control boundary for directory buckets is set only at the bucket level. For more information, see AWS Identity and Access Management (IAM) for S3 Express One Zone.
-
S3 Block Public Access – All S3 Block Public Access settings are enabled by default at the bucket level. This default setting can't be modified.
-
S3 Object Ownership (bucket owner enforced by default) – Access control lists (ACLs) are not supported for directory buckets. Directory buckets automatically use the bucket owner enforced setting for S3 Object Ownership. Bucket owner enforced means that ACLs are disabled, and the bucket owner automatically owns and has full control over every object in the bucket. This default setting can't be modified.
-
AWS Identity and Access Management (IAM) – IAM helps you securely control access to your directory buckets. You can use IAM to grant access to bucket management (Regional) API operations and object management (Zonal) API operations through the
s3express:CreateSessionaction. For more information, see AWS Identity and Access Management (IAM) for S3 Express One Zone. Unlike object-management actions, bucket management actions cannot be cross-account. Only the bucket owner can perform those actions. -
Bucket policies – Use IAM-based policy language to configure resource-based permissions for your directory buckets. You can also use IAM to control access to the
CreateSessionAPI operation, which allows you to use the Zonal, or object management, API operations. You can grant same-account or cross-account access to Zonal API operations. For more information about S3 Express One Zone permissions and policies, see AWS Identity and Access Management (IAM) for S3 Express One Zone. -
IAM Access Analyzer for S3 – Evaluate and monitor your access policies to make sure that the policies provide only the intended access to your S3 resources.
Logging and monitoring
S3 Express One Zone uses the following S3 logging and monitoring tools that you can use to monitor and control how your resources are being used:
-
Amazon CloudWatch metrics – Monitor your AWS resources and applications by using CloudWatch to collect and track metrics. S3 Express One Zone uses the same CloudWatch namespace as other Amazon S3 storage classes (
AWS/S3) and supports daily storage metrics for directory buckets:BucketSizeBytesandNumberOfObjects. For more information, see Monitoring metrics with Amazon CloudWatch. -
AWS CloudTrail logs – AWS CloudTrail is an AWS service that helps you implement operational and risk auditing, governance, and compliance of your AWS account by recording the actions taken by a user, role, or an AWS service. For S3 Express One Zone, CloudTrail captures Regional endpoint API operations (for example,
CreateBucketandPutBucketPolicy) as management events. These events include actions taken in the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS SDKs, and AWS API operations. Theeventsourcefor CloudTrail management events for S3 Express One Zone iss3express.amazonaws.com. For more information, see Amazon S3 CloudTrail events.
Note
Amazon S3 server access logs aren't supported with S3 Express One Zone.
Object management
After you create a directory bucket, you can manage your object storage by using the Amazon S3 console, AWS SDKs, and AWS CLI. The following features are available for object management with S3 Express One Zone:
-
S3 Batch Operations – Use Batch Operations to perform bulk operations on objects in directory buckets, for example, Copy and Invoke AWS Lambda function. For example, you can use Batch Operations to copy objects between directory buckets and general purpose buckets. With Batch Operations, you can manage billions of objects at scale with a single S3 request by using the AWS SDKs or AWS CLI or a few clicks in the Amazon S3 console.
-
Import – After you create a directory bucket, you can populate your bucket with objects by using the import feature in the Amazon S3 console. Import is a streamlined method for creating Batch Operations jobs to copy objects from general purpose buckets to directory buckets.
AWS SDKs and client libraries
After you create a directory bucket and upload an object to your bucket, you can manage your object storage by using the following.
-
Mountpoint for Amazon S3
– Mountpoint for Amazon S3 is an open-source file client that delivers high-throughput access, lowering compute costs for data lakes on Amazon S3. Mountpoint for Amazon S3 translates local file system API calls to S3 object API calls like GETandLIST. It is ideal for read-heavy data lake workloads that process petabytes of data and need the high elastic throughput provided by Amazon S3 to scale up and down across thousands of instances. -
S3A
– S3A is a recommended Hadoop-compatible interface for accessing data stores in Amazon S3. S3A replaces the S3N Hadoop file system client. -
PyTorch on AWS – PyTorch on AWS is an open-source deep-learning framework that makes it easier to develop machine learning models and deploy them to production.
-
AWS SDKs
– You can use the AWS SDKs when developing applications with Amazon S3. The AWS SDKs simplify your programming tasks by wrapping the underlying Amazon S3 REST API. For more information about using the AWS SDKs with S3 Express One Zone, see AWS SDKs.
Encryption and data protection
Objects stored in directory buckets are automatically encrypted by using server-side encryption with Amazon S3 managed keys (SSE-S3). Directory buckets don't support server-side encryption with AWS Key Management Service (AWS KMS) keys (SSE-KMS), server-side encryption with customer-provided encryption keys (SSE-C), or dual-layer server-side encryption with AWS KMS keys (DSSE-KMS). For more information, see Data protection and encryption and Using server-side encryption with Amazon S3 managed keys (SSE-S3).
S3 Express One Zone offers you the option to choose the checksum algorithm that is used to validate your data during upload or download. You can select one of the following Secure Hash Algorithms (SHA) or Cyclic Redundancy Check (CRC) data-integrity check algorithms: CRC32, CRC32C, SHA-1, and SHA-256. MD5-based checksums are not supported with the S3 Express One Zone storage class.
For more information, see S3 additional checksum best practices.
AWS Signature Version 4 (SigV4)
S3 Express One Zone uses AWS Signature Version 4 (SigV4). SigV4 is a signing protocol used to authenticate requests to Amazon S3 over HTTPS. S3 Express One Zone signs requests by using AWS Sigv4. For more information, see Authenticating Requests (AWS Signature Version 4) in the Amazon Simple Storage Service API Reference.
Strong consistency
S3 Express One Zone provides strong read-after-write consistency for PUT and
DELETE requests of objects in your directory buckets in all
AWS Regions. For more information, see Amazon S3 data consistency model.
Related services
You can use the following AWS services with the S3 Express One Zone storage class to support your specific low-latency use case.
-
Amazon Elastic Compute Cloud (Amazon EC2) – Amazon EC2 provides secure and scalable computing capacity in the AWS Cloud. Using Amazon EC2 lessens your need to invest in hardware up front, so you can develop and deploy applications faster. You can use Amazon EC2 to launch as many or as few virtual servers as you need, configure security and networking, and manage storage.
-
AWS Lambda – Lambda is a compute service that lets you run code without provisioning or managing servers. You configure notification settings on a bucket, and grant Amazon S3 permission to invoke a function on the function's resource-based permissions policy.
-
Amazon Elastic Kubernetes Service (Amazon EKS) – Amazon EKS is a managed service that eliminates the need to install, operate, and maintain your own Kubernetes control plane on AWS. Kubernetes
is an open-source system that automates the management, scaling, and deployment of containerized applications. -
Amazon Elastic Container Service (Amazon ECS) – Amazon ECS is a fully managed container orchestration service that helps you easily deploy, manage, and scale containerized applications.
-
Amazon Athena – Athena is an interactive query service that makes it easy to analyze data directly in Amazon S3 by using standard SQL. You can also use Athena to interactively run data analytics by using Apache Spark without having to plan for, configure, or manage resources. When you run Apache Spark applications on Athena, you submit Spark code for processing and receive the results directly.
-
Amazon SageMaker Runtime Model Training – Amazon SageMaker Runtime is a fully managed machine learning service. With SageMaker Runtime, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment.
-
AWS Glue – AWS Glue is a serverless data-integration service that makes it easy for analytics users to discover, prepare, move, and integrate data from multiple sources. You can use AWS Glue for analytics, machine learning, and application development. AWS Glue also includes additional productivity and data-ops tooling for authoring, running jobs, and implementing business workflows.
-
Amazon EMR – Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data.
Next steps
For more information about working with the S3 Express One Zone storage class and directory buckets, see the following topics:
